最强AI视频配音,MMAudio,根据视频画面自动配上音乐、音效,一键启动整合包!解压即用,完全免费!
前置说明
- 本AI工具基于 Github 开源项目 MMAudio,由B站博主<与AI同行1996>整合开发的一键整合包。
- 本AI工具对于设备性能有较高的要求,不支持非独立显卡设备,对于显卡性能、显存大小不足的设备,生成速度不佳。
- 本AI工具适用于给静音视频自动生成合适的画面音效配音,不是人声朗读配音工具
- 使用中命令行窗口报错提示可以暂时忽略,不影响使用
- 关于本程序的所有文件目录不要有中文文字和符号,包括软件文件夹、视频名称,否则可能会报错!
- 仅支持英伟达显卡,AMD显卡无法使用!!
功能特性
- 基于 Github 开源项目 MMAudio 开发
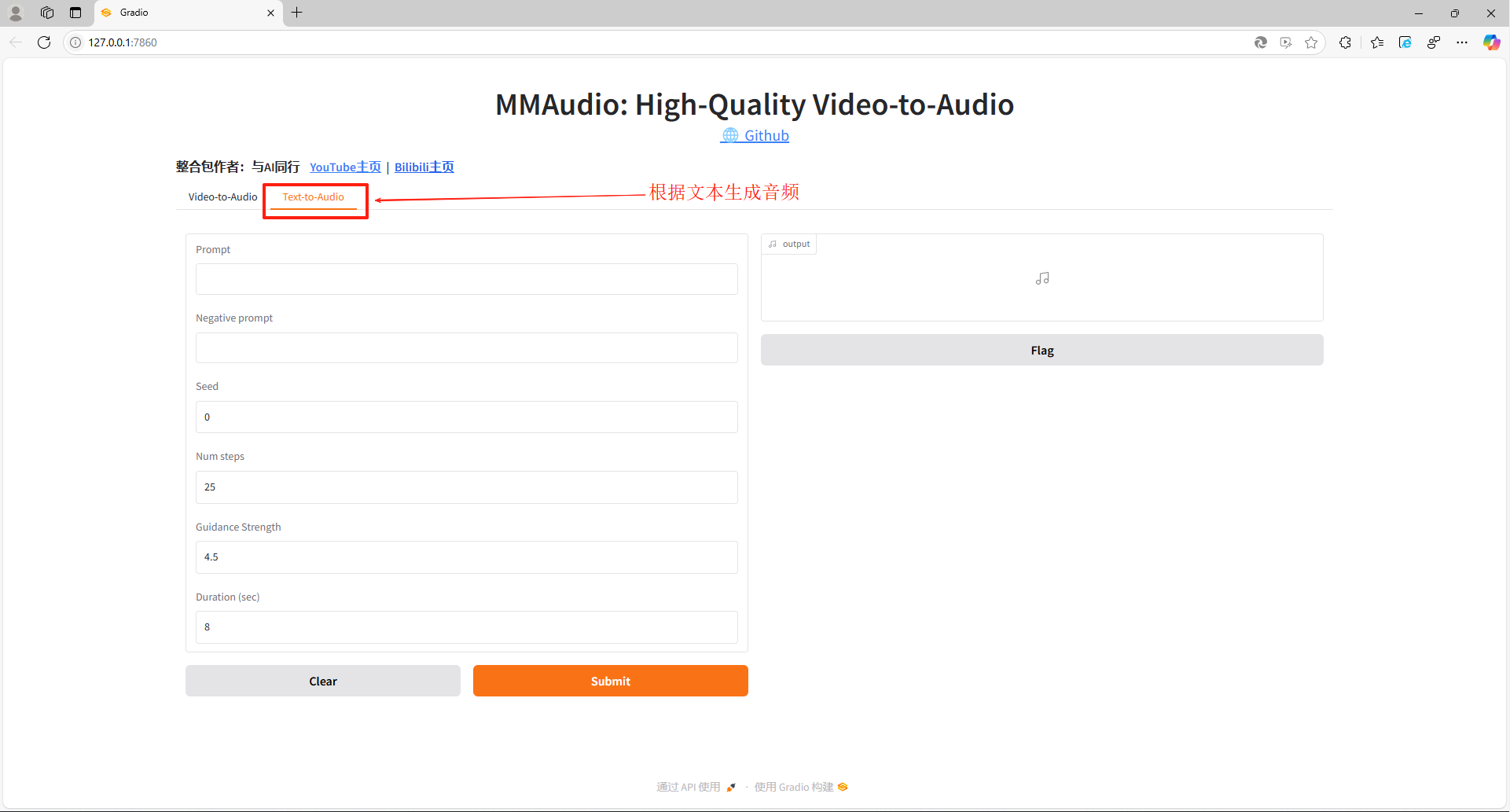
- 支持根据视频画面自动配上音效或音乐
- 支持仅根据文本提示词生成对应的音效或音乐
- 支持针对与视频画面搭配提示词生成对应的音效或音乐
- 允许使用正、负面提示词
效果演示
推荐配置
- 仅支持英伟达显卡,暂不支持AMD显卡设备,显存至少大于等于8G
- 6G显存理论也能使用,但是会调用共享显存,所以生成速度非常非常缓慢
- Windows 10及以上系统
快速开始
此开源工具整合作者在bilibili发布有详细的工具使用教程,感兴趣的可以直接前往bilibili观看原作者的完整配置教程。如果你赶时间想要快速上手操作,观看文字教程,请继续下滑到我们的文字基础教程。
文字基础教程
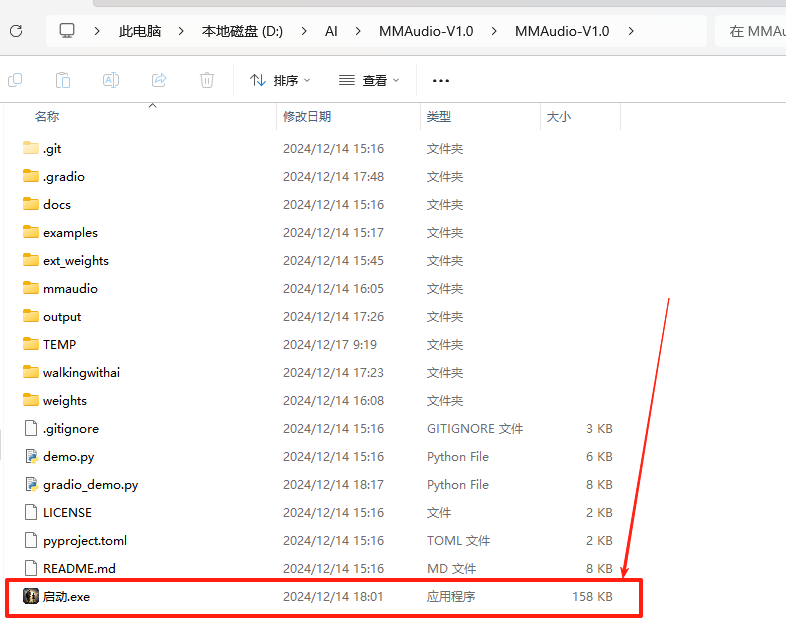
第一步:将下载的压缩包解压到英文路径下,并点击打开,下滑找到 启动.exe 程序双击运行
注意:安装解压目录尽量不要有中文!!!首次运行可能需要较长的时间,请耐心等待!
第二步:准备好需要进行AI配音的视频静音素材,存放在英文路径下,并且文件名也设置为英文
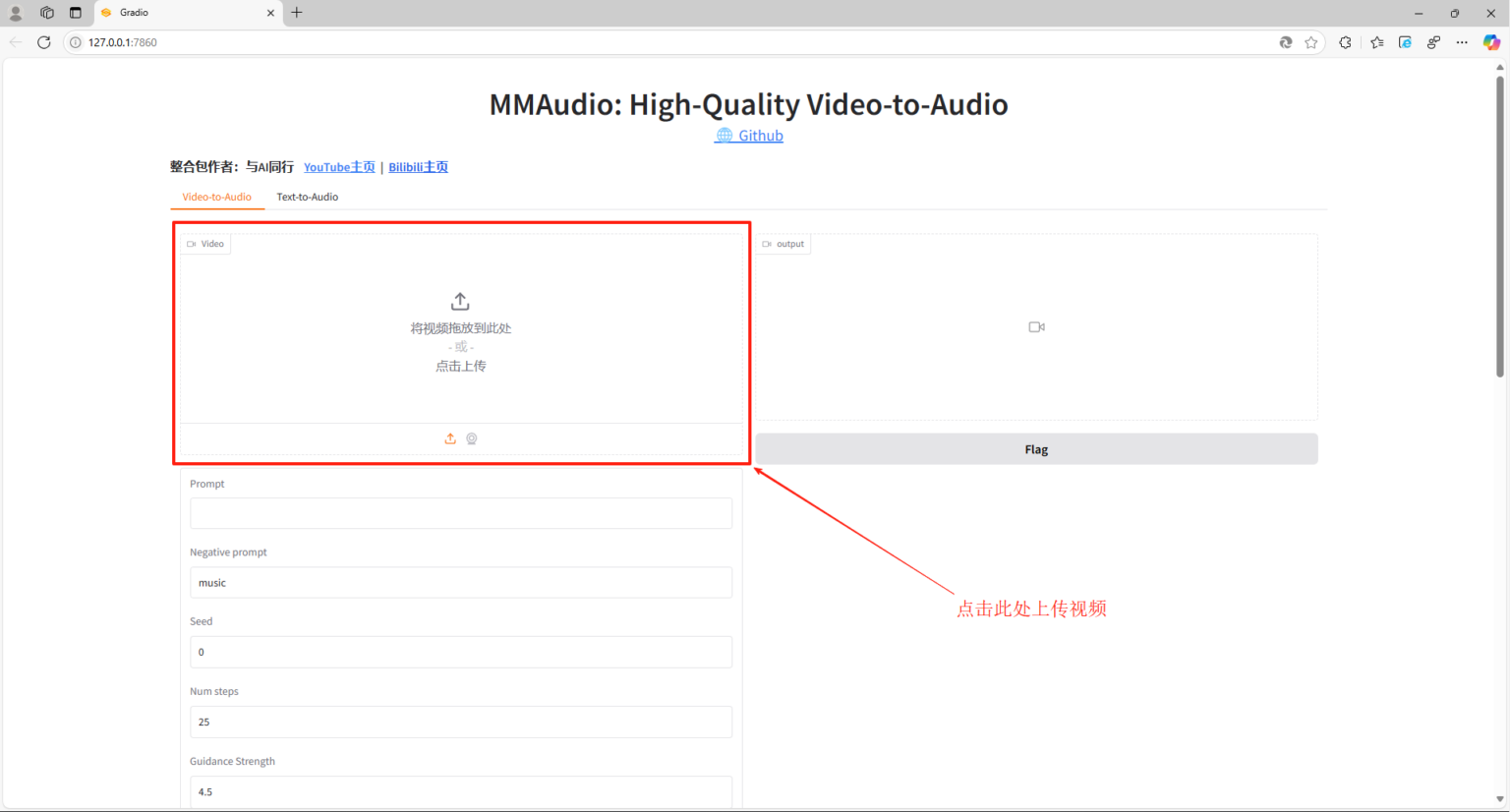
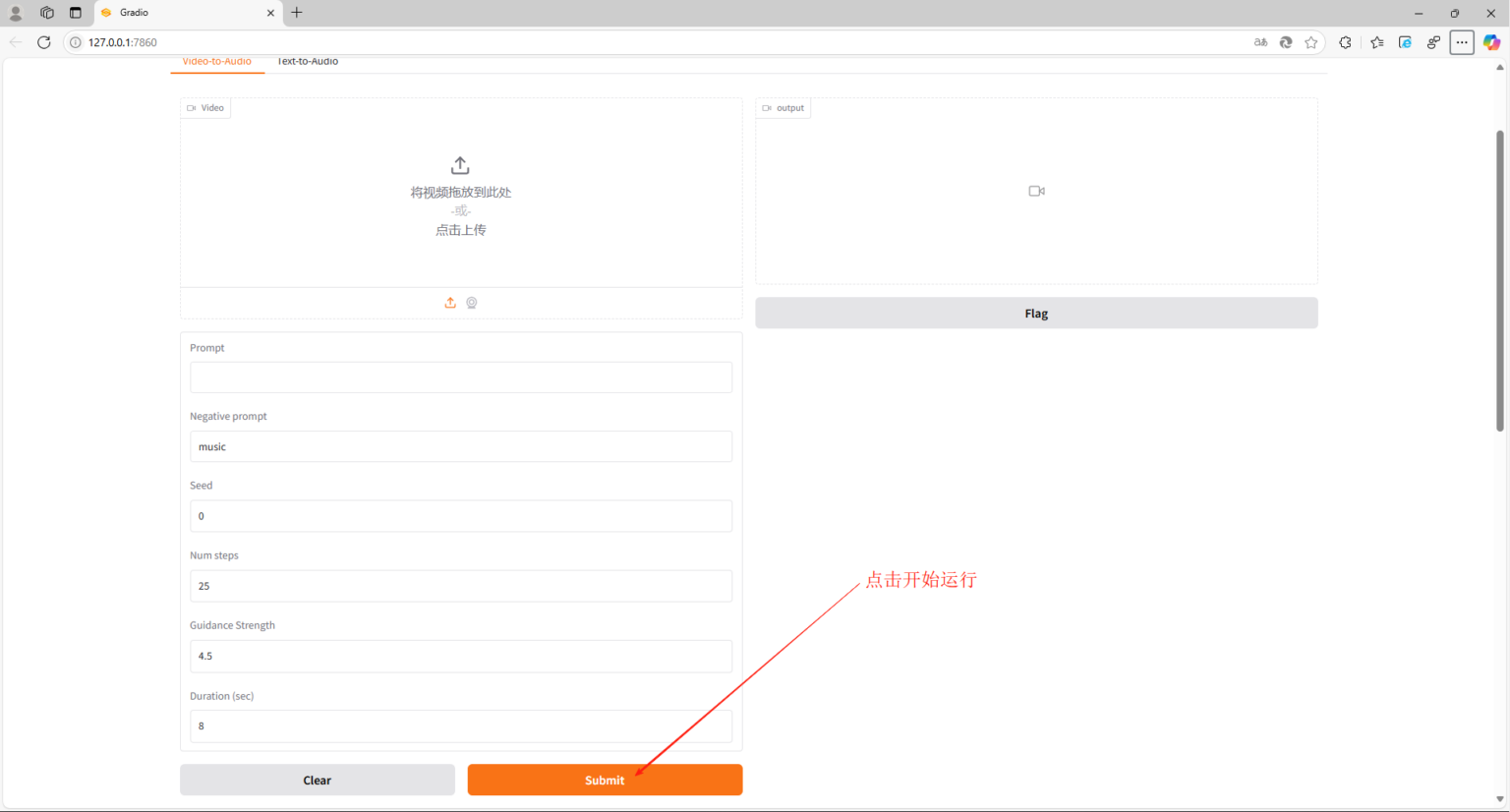
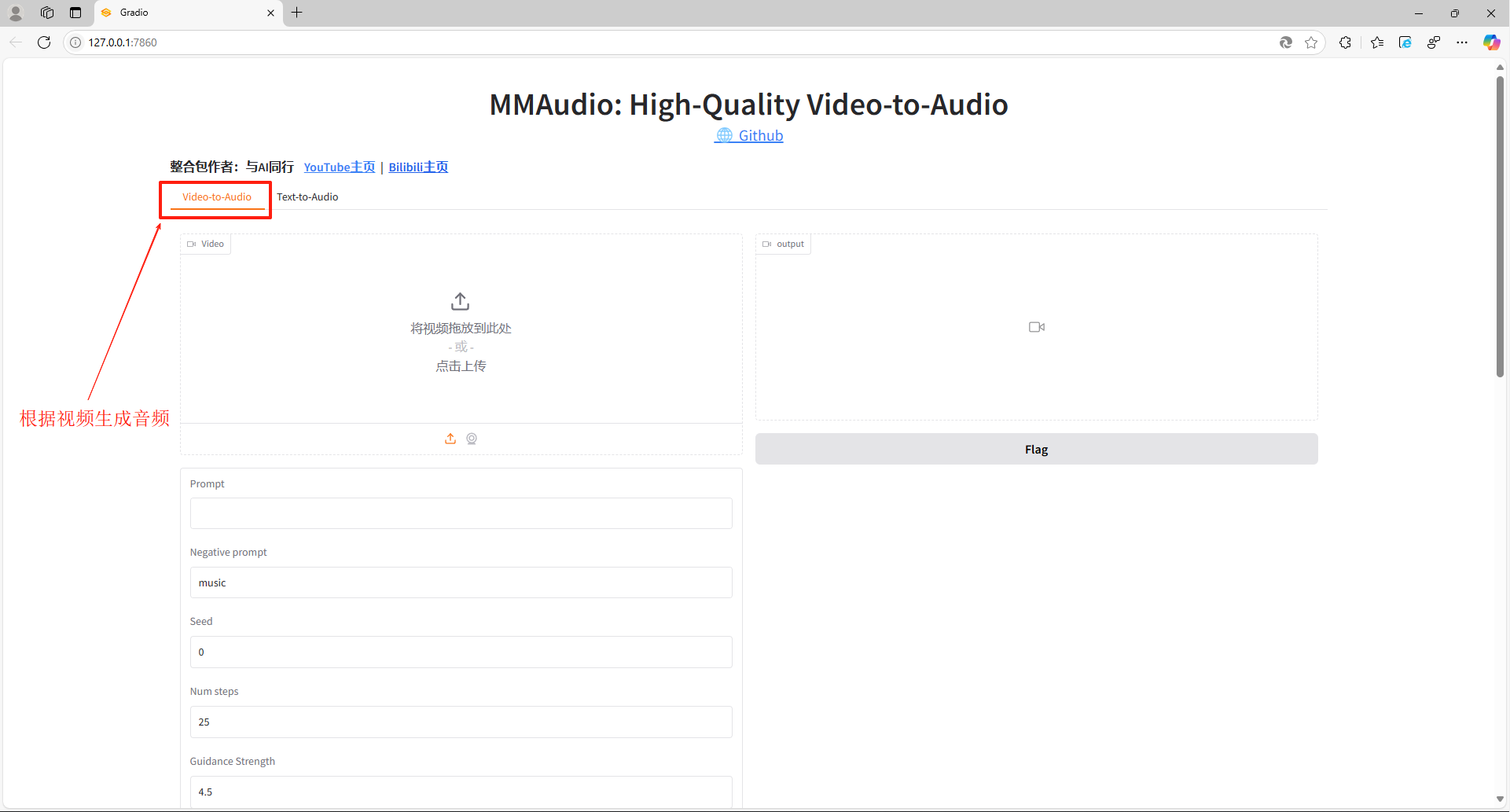
第三步:启动之后,程序会自动打开浏览器WebUI窗口,在页面中,可以看到程序有两种运行模式,一种是 Video-to-Audio(根据视频生成音频),一种是 Text-to-Audio(根据文本生成音频),我们按需要选择切换对应的功能菜单下进行进一步的操作设置。
注意:如果你的程序启动之后无法自动调起浏览器窗口,您也可以在程序启动之后,手动在浏览器地址栏输入 127.0.0.1:7860/ 进行访问。
第四步:以 Video-to-Audio(根据视频生成音频)为例,点击页面中上传栏,将我们需要处理的无声素材导入进去(注意:素材的文件路径和文件名都不要包含中文字符!)
第五步:根据需要,分别设置下面的参数,以达到更准确的产出效果,或者您也可以不做任何更改直接让AI以默认参数运行。修改完之后,点击下方的 Submit 开始运行。
注意:所有提示词需使用英文!!
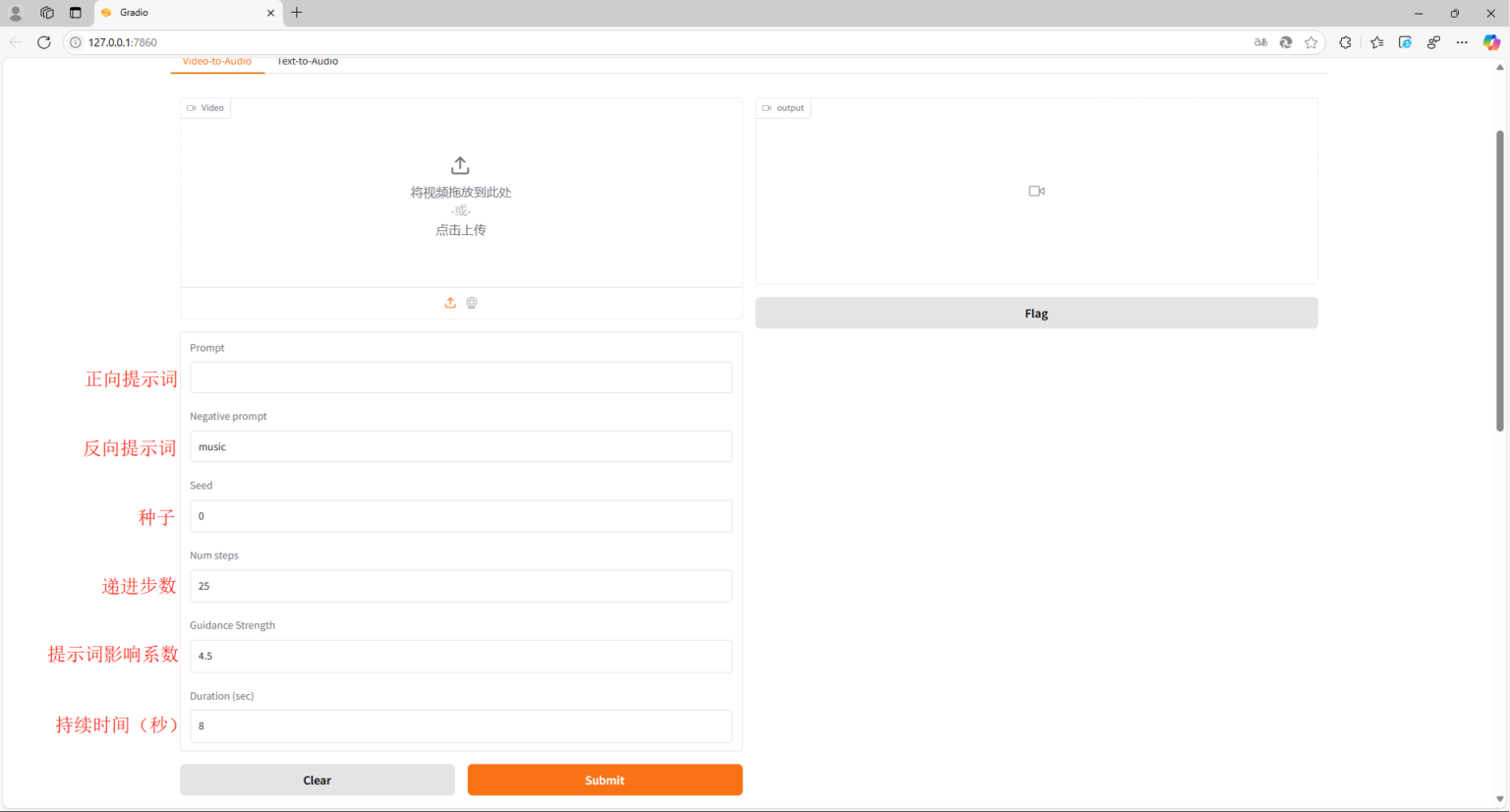
参数解释:
- Prompt(正向提示词):在与生成式 AI 模型交互时提供的输入文本或指令,这个输入内容用来引导模型生成特定的输出结果。
- Negative prompt(反向提示词,或负面提示词):是生成式 AI 模型中特有的一个概念,它用于告诉模型你不想要生成的内容,也就是排除掉不需要的元素或特征。
- Seed(种子):用于初始化随机数生成器的值。它决定了生成内容的随机性,同时也可以确保结果的可复现性,生成式 AI 依赖随机数来创造内容,每次输入相同的提示词(Prompt)时,如果没有指定种子,输出结果通常会有所不同。指定相同的 Seed 和 Prompt,可以生成完全一致的结果。
- Num steps(步数):用于控制生成图像或内容时的迭代次数。它决定了模型从随机噪声逐步优化、精炼成最终结果所经历的步骤数量。
- Guidance Strength(提示词引导强度):它决定了输出结果与提示词的匹配程度,以及生成图像或内容的创意自由度。
- Duration (sec)(持续时间(秒)):生成的音频持续时间,数值以秒为单位
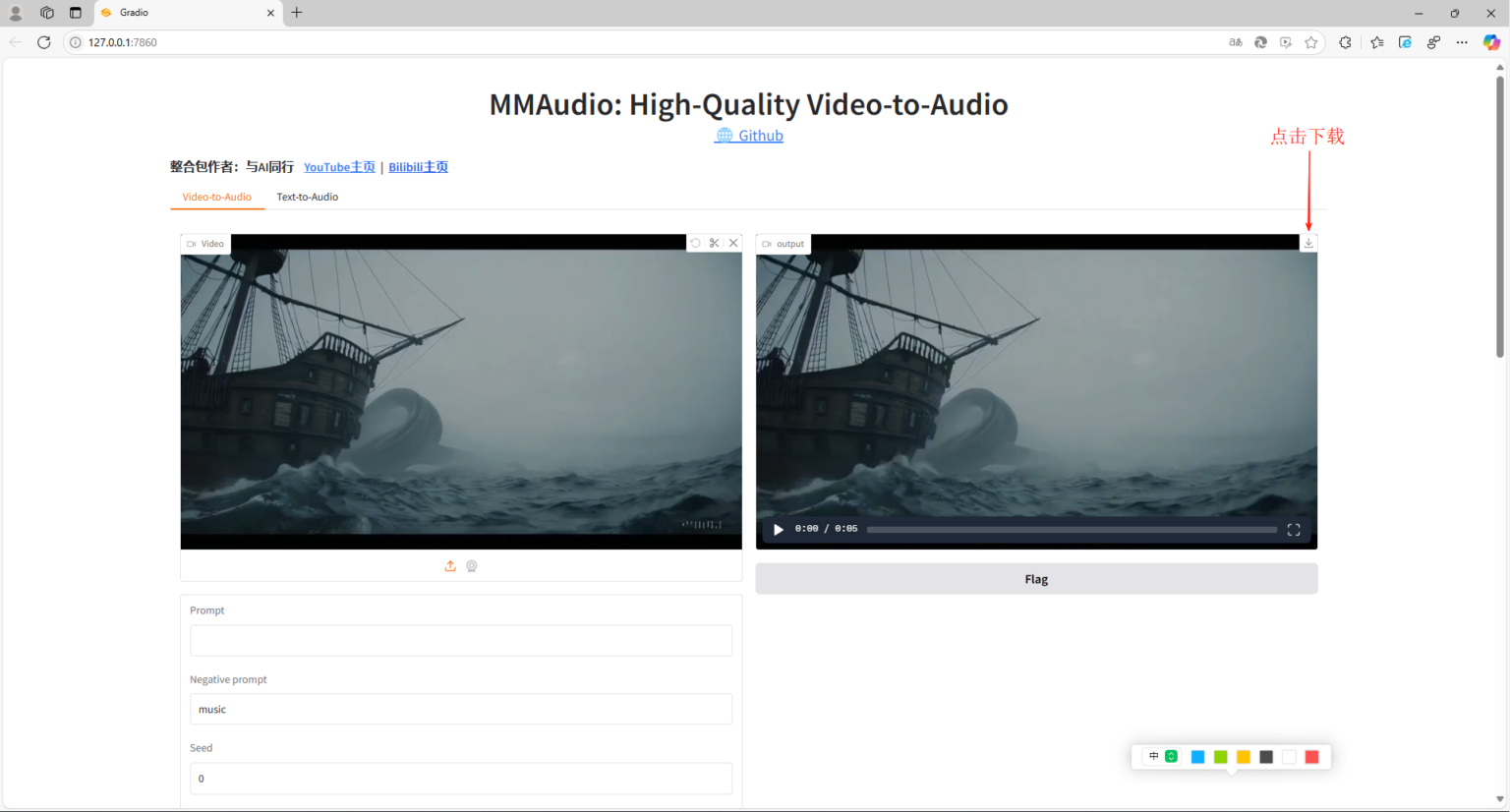
第六步:运行结束之后,我们在右侧的窗口中可以看到处理结果,可以直接在窗口中播放预览,检查没问题之后,点击右上角的下载图标,可以将文件保存在本地。
提示:处理速度取决于您的视频时长、显卡性能以及显存大小,显卡性能越好,处理速度越快。实测1660Super 6G显存对比3060 8G显存处理速度相差十几倍,1660Super 6G显卡速度慢,但是也可以进行处理,质量一样,只是速度很慢。

![AI视频音效配音的使用截图[1]](https://moqingtk.com/wp-content/uploads/2024/12/1734400120-image.png)